Análisis categorial y sintáctico
Contents
3. Análisis categorial y sintáctico#
Borja Navarro Colorado
Nota
Para preparar este tema, tras leer este documento, debes leer los capítulos 8 y 18 de Jurafsky y Martin (2023) Speech and Language Processing. https://web.stanford.edu/~jurafsky/slp3/. Durante la explicación a continuación se indica qué secciones son las más relevantes. Al final de esta página y en la sección “Actividades previas” tienes el enlace para realizar el cuestionario de aprendizaje. Recordad que debéis realizarlo ANTES de la próxima clase: tenéis de plazo hasta las 23:59 del 07/02/2023 (el día anterior a la clase presencial). También puedes acceder al cuestionario desde la sección “Actividades previas”.
3.1. Unidades de comunicación básica. La palabra. Type, token y lema.#
Si bien el concepto de “palabra” se suele utilizar como unidad mínima y básica de comunicación, realmente la palabra “palabra” no tiene en lingüística una definición clara: es un concepto vago muy difícil de delimitar.
En lingüística de corpus, lingüística computacional y procesamiento del lenguaje natural, más que con el concepto de “palabra”, se trabaja con los conceptos de type (“tipo”) y token (“caso”) (introducidos por el filósofo Charles S. Peirce a principio de siglo XX):
Type es la palabra entendida como clase o tipo. Una secuencia de caracteres diferente de cualquier otra secuencia.
Token es cada una de las instancias o casos concretos de esas clase type que se pueda hallar en un texto 1.
Se suele ejemplificar la diferencia entre ambos conceptos con el verso de G. Stein:
“Rose is a rose is a rose is a rose”;
pero para españolizarlo un poco vamos a coger como ejemplo el siguiente verso de esta canción de Mecano, que es una versión simplificada del verso de Stein:
“Una rosa es una rosa es”.
En este verso encontramos tres types:
“una”
“rosa”
“es”;
pero seis tokens: 2 tokens del type “una”, 2 del type “rosa” y 2 del type “es”. Son por tanto \(2+2+2 = 6\) tokens. Este texto está formado por seis tokens y tres types.
Como se puede comprobar, esta diferencia es la base conceptual del cálculo de frecuencias textuales. El cálculo más simple es contar, como se ha hecho antes, la cantidad de tokens de cada type en un texto:
type |
tokens |
|---|---|
una |
\(2\) |
rosa |
\(2\) |
es |
\(2\) |
En esta línea, el tamaño de un corpus siempre se mide en cantidad de tokens.
3.1.1. Tokenización#
El primer paso a la hora de procesar un texto es, por tanto, hallar los tokens y, con ello, los types que forman el texto. A este proceso se le denomina tokenización.
El método de tokenización más simple es separar cada token por espacio en blanco. Token quedaría así definido como la secuencia de caracteres separada por un espacio en blanco. Desde un punto de vista lingüístico, esta aproximación presenta algunas limitaciones:
Los signos de puntuación son un type diferente, pero aparecen pegados a la palabra anterior o posterior. Es necesario algún tipo de regla más allá del espacio en blanco que separe los signos de puntuación.
Hay unidades lingüísticas que están formadas por más de un type. Me refiero a las llamadas “unidades multipalabra”, como por ejemplo las formas complejas de los verbos: “he comido”, “había creídos”, “fue resuelto”, etc.
La situación contraria se produce con las contracciones como “del” o “al” y en general formas aglutinantes (“dáselo”). En este caso se podría considerar types diferentes porque responde a diferentes palabras y habría que separarlas.
Un tokenizador estándar resuelve el primer problema de los signos de puntuación, pero no los otros dos. Esto se deja para el lematizador, que se comentará después.
Por otro lado, no siempre la tokenización depende del espacio en blanco. Como se comentó antes, un token es la instancia de un type. Este puede ser cualquier secuencia de caracteres que se repitan en el texto, incluso se podría tokenizar por caracteres individuales. Los sistemas neuronales, por ejemplo, explotan diversas formas de tokenización para mejorar los análisis. En capítulos siguiente se verá cómo. Los sistemas de PLN estándar suelen trabajar con la tokenización por espacio en blanco. La herramienta NLTK (Natural Language Toolkit) dispone de diferentes tokenizadores.2
3.1.2. Lematización y stemming#
Type y token se refieren siempre a formas flexionadas, es decir, a formas con variaciones morfológicas. Así, “catamos” y “cantaré” son types distintos; al igual que “casa” y “casas”.
Para agrupar todos los tokens relacionados con la misma palabra (es decir, la forma sin flexionar) se realiza un proceso de lematización. La lematización consiste en asignar a cada palabra lo que en lingüística se denomina su “forma no marcada” o lema: el infinitivo para verbos, o la forma masculino singular para nombres y adjetivos. La forma no marcada es la que aparece en el diccionario. El lema es una manera de nombrar la palabra en toda su diversidad flexiva.
La lematización es un fenómenos complejo porque para saber el lema de un token es necesario analizar morfológicamente la palabra. Hay muchos casos de ambigüedad. Por ejemplo, el lema del token “traje” puede ser tanto “traer” (si es verbo) como “traje” (si es nombre), como en el siguiente texto:
¿Usted no nada nada?
Es que no traje traje.
Por ello en algunas aplicaciones como en recuperación de información, en vez de una lematización completa, se utiliza un proceso similar pero más rápido y sencillo denominado stemming. Este consiste en reducir cada token a su raíz o lexema, es decir, la parte invarible del token (siempre y cuando responda a una flexió morfológica regular) que, en principio, asume el significado general de la palabra. Así, por ejemplo, de las diferentes formas del verbo “amar” (“amaría, amaré, amado, ame,” etc.), un stemmer reduciría cada token a su raíz “am-”, mientras que un lematizador lo relacionaría con el lema “amar”.
3.2. Análisis morfológico y categorial.#
La herramienta de PLN que realiza el análisis morfológico y categorial es el Part of Speech tagger (pos_tagger o analizador categorial).
El objetivo principal de una analizador categorial es asignar a cada token de un texto su categoría gramatical correspondiente, incluidos signos de puntuación. En concreto, los datos que analiza un pos_tagger estándar suelen ser, por cada token:
el lema,
la categoría gramatical (“nombre, verbo, adjetivo, …”),
rasgos morfológicos (género, número, voz, tiempo, etc.).
El mayor problema que resuelve un analizador categorial es la ambigüedad categorial que vimos anteriormente: aquellos tokens que pueden pertenecer a dos o más categorías gramaticales.
3.2.1. Algunos conceptos lingüísticos.#
A modo de recordatorio, en esta sección se repasan algunos conceptos lingüísticos que se deben tener claros para trabajar con PoS_taggers.3
Las palabras de un idioma se clasifican en categorías gramaticales o “clases de palabras”. Cada categoría agrupas palabras que tienen un comportamiento lingüístico similar: palabras con rasgos distributivos y morfológicos similares, y en algunos casos también rasgos semánticos parecidos.
Si bien no hay una lista fija de categorías gramaticales (las diferentes teorías suelen presentar pequeñas variantes), en español las categorías gramaticales suelen ser: determinantes (incluyendo aquí artículos, demostrativos, posesivos, numerales e indefinidos), sustantivos, adjetivos, pronombres, verbos, adverbios, preposiciones, conjunciones e interjecciones.
Estas clases se agrupan en dos grandes grupos: las categorías abiertas y cerradas. Las abiertas son aquellas en las que constantemente está apareciendo palabras nuevas (neologismos) y desapareciendo otras (arcaísmos): nombres, verbos y adjetivos sobre todo. Las clases cerradas son las clases más estables porque apenas cambian en el tiempo (preposiciones, determinantes, conjunciones, interjecciones principalmente).
Este diferencia es relevante desde el punto de vista computacional por dos hechos:
Todo sistema de PLN debe estar preparado para analizar palabras nuevas. En una clase abierta el sistema de PLN se puede encontrar con palabras que no ha visto nunca antes (bien porque no está en el diccionario, bien porque no está en los corpus de aprendizaje, o bien simplemente porque es un neologismo) y debe ser capaz de analizarla. Este problema se da sobre todo con los nombres. Los sistemas neuronales actuales han mostrado ser muy eficaces para tratar este problema.
Las clases cerradas suelen estar formadas por pocas palabras. Esto provoca que la frecuencia de uso de las palabras de clases cerradas (preposiciones, conjunciones, pronombres, etc.) sea muy alta. Así, al extraer las frecuencias de cualquier texto encontramos pocas palabras con frecuencias muy altas (las palabras de categorías cerradas) y muchas palabras con frecuencias muy bajas (el llamado hápax legómena, que se produce por la gran cantidad de palabras de categorías abiertas que aparecen solo una vez). Esto complica los análisis de frecuencia. Para evitar esta situación, las palabras de categorías cerradas se suelen filtrar antes de extraer frecuencias: son las llamadas stop words.
Por su flexión, hay categorías cuyas palabras son variables o “flexivas” y categorías de palabras invariables. Son categorías variables los nombres (con flexión de género y número), verbos (con flexión en tiempo, modo, voz, aspectos, número y persona), adjetivos (género, número y grado), pronombres y algunos adverbios y determinantes. La flexión tiene implicaciones semánticas, por lo que su análisis es más complejo. Esta es la razón de ser del análisis morfológico completo, donde de cada token se especifica automáticamente no solo su categoría gramatical, sino también sus rasgos flexivos.
Finalmente, por su función en el texto, se diferencia entre clases de palabras con significado léxico (nombres, verbos, adjetivos, adverbios) y clases de palabras con “significado” gramatical (determinantes, preposiciones, pronombres, etc.). Este significado gramatical no es significado pleno. Se refiere a que esas palabras pueden modificar o determinar el significado de las palabras con significado léxico con las que aparecen, pero en sí mismas y por sí solas no podemos decir que tengan un significado completo. Una preposición como “ante”, por ejemplo, podemos intuir rasgos semánticos (“frente a algo o delate de algo”), pero su función es completar ese “algo” con indicación de posición (“se paró ante de la puerta”).
3.2.2. Relevancia del análisis categorial en minería de textos#
Así como un proceso de tokenización es un paso inleduble para realizar minería de textos, el análisis categorial no siempre es necesario. Éste es un proceso que requiere recursos computacionales y, si el corpus es muy amplio, también mucho tiempo de procesamiento. Por ello se debe tener claro qué se necesita para valorar si es necesario utilizar un pos tagger o no.
Un análisis categorial es en muchas ocasiones la base del sistema de PLN, porque los análisis sintácticos y muchos de los análisis semánticos y pragmáticos dependen de las clases de palabras: necesitan saber el lema de cada token, la clase de palabra a la que pertenecen y/o sus rasgos morfológicos.
Un proceso muy común en minería de texto y de poco coste computacional es realizar un filtro de “stop words”: eliminar todas aquellas palabras que pertenecen a categorías cerradas y que no tienen significado léxico (preposiciones, conjunciones, artículos, etc.). Este filtrado NO necesita realizar el análisis categorial completo: como son categorías cerradas (es, por tanto, un conjunto finito de palabras), se pueden listar en un fichero y filtrar con un simple pattern matching. También un proceso de stemming requiere poco tiempo de proceso (no es necesario realizar todo el análisis categorial) y permitiría tratar token de categorías flexivas como un solo type.
Otras aplicaciones de minería de textos sí dependen de las categorías gramaticales y por tanto requieren realizar el análisis categorial y morfológico. Entre otras:
la extracción de entidades necesita saber qué palabras son nombres y en especial los nombres propios;
la extracción de eventos necesita saber qué palabras son verbos y qué palabras son nombres;
el análisis de sentimientos y opiniones depende mucho de los adjetivos;
la detección de autoría determina automáticamente quién es el autor de un texto sobre todo por cómo se utilizan las palabras de categorías cerradas (preposiciones, conjunciones, etc). Se ha demostrado que sus frecuencias de uso depende mucho del estilo personal de escritura de cada persona. La frecuencia de uso de otras clases de palabras como nombres o verbos depende más del tema del texto y no suelen ser buenos indicadores para detectar automáticamente la autoría de un texto.
etc.
3.2.3. Representación formal de la información morfológica y categorial#
Antes de exponer los métodos de análisis categorial, vamos a ver cómo se representa formalmente esta información lingüística.
La información categorial y morfológica se representa explícitamente mediante etiquetas o tags. Actualmente hay diversas propuestas, cada una con un juego de etiquetas diferente. Antes de usar un PoS_tagger, es muy importante saber con qué juego de etiquetas representa la información para poder luego interpretar la información correctamente. Las listas de etiquetas (o tag sets) comunes hoy día en PLN son los siguientes:
Penn Treebank tag set (solo para inglés):
Ejemplos:
JJ = adjetivo NN = nombre común VB = verbo ...
Universal tagset (Universal dependencies project):
Ejemplos:
ADJ = adjetivo NOUN = nombre VERB = verbo ...
Este modelo, el más utilizado hoy día, está adaptado a más de 50 idiomas (y sigue creciendo). Es el más apropiado para minería de textos multilingüe. Ver https://universaldependencies.org/
EAGLES tag set (para varios idiomas):
http://blade10.cs.upc.edu/freeling-old/doc/tagsets/tagset-es.html
https://freeling-user-manual.readthedocs.io/en/latest/tagsets/
Ejemplo:
AQ0CP0 = adjetivo calificativo común plural NCFP000 = nombre común femenino plural VMIP1S0 = verbo principal indicativo presente primera persona singular ...
Este tipo de etiqueta es más complejo pero contiene bastante información. Cada posición es un rasgo morfológico. El primero (A, N, V, etc.) indica la categoría gramatical. El resto de posiciones, dependiendo de la categoría, aporta una información morfológica u otra. Así, para nombre, las posiciones indican:
1 categoría
2: tipo: común o propio
3: género
4 número
5-6 rasgos semántico
7 grado
Ver las tablas para saber qué información contiene cada posición del resto de categorías.
Este modelo se planteó como un modelo multilingüe. Así, no todas las palabras de todos los idiomas tienen esa información morfológica. Si una palabra no tiene un rasgo morfológico determinado, en la etiqueta aparece \(0\).
Por ejemplo, en la etiqueta “NCFP000” no es relevante ni el rasgo semántico (codificado como 00) ni el grado (codificado como 0). Sí es relevante la categoría (N: nombre), el tipo (C: común), el género (F: femenino) y el número (P: plural). Esta etiqueta se asociaría por ejemplo a la palabra “camisas”.
Como se puede observar, los tag sets utilizados en PLN suelen tener más categorías que las utilizadas en lingüística teórica. Por ejemplo, presentan etiquetas específicas para los signos de puntuación o para números y fechas, entre otros casos.
3.2.4. Arquitectura de un PoS_tagger.#
La siguiente imagen muestra una sencilla arquitectura para un pos_tagger:
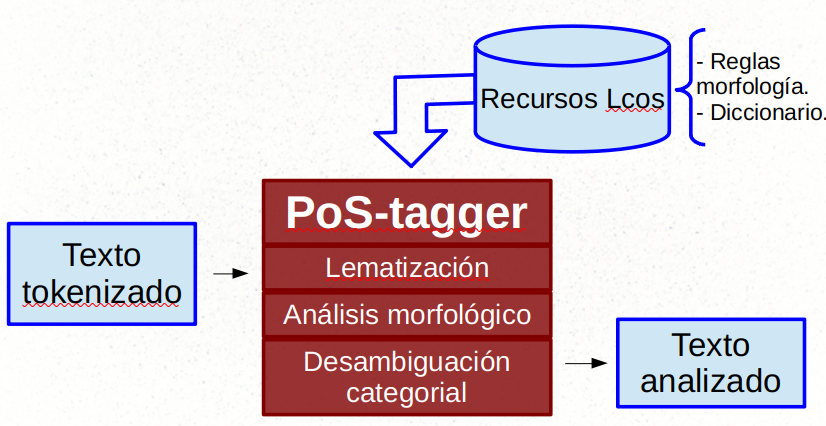
La entrada es un texto que ha sido previamente tokenizado. Los signos de puntuación, por ejemplo, estarán separados de las palabras anterior o posterior (según proceda). La salida será cada token de entrada junto a su información categorial y morfológica. Normalmente, la salida de un pos tagger es:
token lema etiqueta_PoS
Para poder determinar el lema y la categoría de cada token, así como la información morfológica, el pos_tagger necesita algún tipo de recurso. Básicamente dos: un diccionario que contenga la información morfológica de cada palabra; y un conjunto de reglas (gramática) que deriven la información morfológica según los rasgos de la palabra y de las palabras del contexto. Este puede haber sido creado a mano (reglas manuales) o mediante aprendizaje automático. Esto es una analizador en dos fases (consulta diccionario y desambiguación), que es la arquitectura básica de un PoS_tagger.
Un ejemplo de PoS_tagger para español es Freeling. Antes de seguir, prueba su demo:
3.2.5. Algoritmos de desambiguación categorial.#
Si un token solo puede pertenecer a una categoría gramatical, su análisis morfológico es sencillo: basta con consultar el diccionario para saber su categoría. El problema viene cuando un token puede pertenecer a dos o más categorías gramaticales (ambigüedad categorial). Este es el caso más común, pues más del 60% de las palabras de un texto en español suelen presentar ambigüedad categorial. En esta sección se presentan los principales algoritmos para resolver la ambigüedad categorial.
3.2.5.1. Modelo basado en reglas (simbólicos).#
Los primeros sistemas utilizaban reglas morfológica simples creadas a mano por lingüistas. Se seguía el modelo de dos fases: una primera que asigna las categorías gramaticales a cada token según el diccionario, y una segunda que aplica reglas de desambiguación en el caso de que el token tenga asignadas dos o más etiquetas.
Las reglas de desambiguación era básicamente expresiones regulares tipo:
\b.*ing\b = Verbo Infinitivo en inglés.
\b.*mente\b = adverbio en español.
las\s[a-z]*as → Nombre femenino plural en español.
etc.
Ejemplo de esta aproximación es el sistema TAGGIT, de 1971. Constaba de 71 etiquetas y 3300 reglas de desambiguación. Con esto alcanzó un nivel de precisión del 77%.4
La herramienta NLTK tiene implementado un PoS_tagger basado en expresiones regulares que se puede adaptar. Ver https://www.nltk.org/book/ch05.html.
3.2.5.1.1. Gramáticas de restricciones (Constraint grammar)#
En los años 90 hubo un modelo teórico que tuvo buenos resultados en su aplicación al análisis categorial: las gramáticas de restricciones. Este modelo se basa en la idea de que las reglas de la gramática no tienen por qué ser positivas (reglas que digan cómo es el idioma), sino que pueden ser negativas (reglas que digan como NO es el idioma). Estas reglas negativas son las restricciones.
Así, aplicado al análisis categorial, una restricción indicaría no qué categoría sería la apropiada para una palabra dado un contexto, sino que categoría seguro que NO es la apropiada a una palabra dado un contexto. Por ejemplo, esta regla
“Un verbo no va precedido nunca de artículo”.
permitiría analizar correctamente el sintagma:
El cura de la iglesia
“Cura” no puede ser verbo (de “curar”) porque va precedido de un artículo. Por tanto, es un nombre.
El sistema principal basado en restricciones es el sistema ENGCG (Karlsson et al 1995).5
3.2.5.2. Modelos estadísticos#
3.2.5.2.1. Cadena de Markov#
La aplicación de modelos de Markov supuso un gran avance en la desambiguación categorial. La categoría gramatical de un token depende en gran medida del contexto lingüístico donde aparece. Las reglas directas no son capaces de modelar ese contexto, pero los modelos de Markov sí.
Dada una secuencia de estados, la propiedad de Markov asume que es posible predecir el siguiente estado tendiendo en cuenta únicamente el estado presente. Así, dada una secuencia de palabras (cadena), la propiedad de Markov postula que podemos saber la siguiente palabra a partir de la palabra actual. Así, un modelo de Markov predice un token \(w_i\) según la probabilidad de la palabra anterior \(w_{i-1}\):
Este es un modelo de bigramas porque solo tiene en cuenta la palabra anterior y no todas las palabras anteriores \(w_{i-2} \dots w_{i-n}\), que es la asunción principal de la propiedad de Markov.
3.2.5.2.2. Modelo oculto de Markov#
Aplicado a cadena de tokens tendríamos un simple predictor de palabras como el que tenemos en el móvil. Lo característico de su aplicación para análisis categorial es que se aplica no a la secuencia de palabras (la cadena visible de tokens), sino a la secuencia de categorías gramaticales: la cadena oculta de tags. Se considera una cadena oculta porque las categorías gramaticales no están explícitamente en el texto, sino que son inferidas. De ahí el nombre de Modelo Oculto de Markov o Hidden Markov Model (HMM).
El modelo oculto de Markov necesita, así, en dos probabilidades: una probabilidad de transición de un estado a otro de la cadena (la probabilidad del modelo de Markov simple) y además una probabilidad de emisión del estado oculto al estado visible.
Aplicado al análisis categorial, la probabilidad de transición es la probabilidad de una etiqueta categorial \(t_i\) dada la etiqueta categorial de la palabra anterior \(t_{i-1}\).
La probabilidad de emisión es la probabilidad de que una palabra dada \(w_i\) esté asociada a una etiqueta categorial \(t_i\):
Combinando ambos valores obtenemos la predicción final:
Por ejemplo, dado el siguiente sintagma ya comentado:
El cura de la iglesia.
Un modelo oculto de Markov predice perfectamente que ese “cura” es nombre y no es verbo (de “curar”) porque la probabilidad de que un artículo (la categoría del token “El”) esté seguido por un verbo es prácticamente 0. Por lo que la probabilidad más alta es que “cura” sea nombre.
Un modelo oculto de Markov puede ser entrenado a partir de un corpus anotado, pero también se puede entrenar de manera iterativa con corpus sin anotar, tomando las palabras no ambiguas como inicio del entrenamiento.
Lectura obligatoria
Lee el apartado “8.4 HMM Part-of-Speech Tagging” del capítulo 8 del libro de Jurafsky y Martin (2022) Speech and Language Processing, donde aprenderás los detalles matemáticos y computacionales del análisis categorial basado en modelos ocultos de Markov.
3.2.5.2.3. Conditional Random Fields y otros.#
Si bien con modelos ocultos de Markov un PoS_tagger puede tener una precisión superior al 90%, aún hay aspectos en los que no funciona bien, como por ejemplo cómo analizar palabras que no ha visto antes (y por tanto no tiene probabilidad de emisión). Estos problemas se superaron con un modelo matemático también secuencial pero con más relevancia en cuanto al modelado del contexto: conditional random field (CRF o “campo aleatorio condicional”). Este permite un tratamiento más rico del contexto. Lee el apartado “8.5 Conditional Random Fields (CRFs)” del capítulo 8 del libro de Jurafsky y Martin (2022) Speech and Language Processing para más detalles. Esta lectura es opcional.
Modelos ocultos de Markov y Conditional Random Fields son las dos principales aproximaciones al análisis categorial, pero no las únicas. Se han aplicado otro modelos de aprendizaje, tanto supervisados como no supervisados, como árboles de decisión o máquinas de vectores soporte (support vector machine SVM), etc. Un ejemplo que tuvo impacto en su momento fue el “Transformation-based Tagger” de Brill (1995), que aplicaba un modelo iterativo de aprendizaje de reglas con refinado manual.
3.2.6. Situación actual#
El análisis categorial de las lenguas más habladas se considera una tarea prácticamente resuelta. Las dos líneas de investigación principales son:
desarrollar analizadores multilingües (en la línea, por ejemplo, de las Dependencias Universales que se verá luego); y
aplicar redes neuronales, que es hoy día el modelo estándar. En próximos temas se verán las redes neuronales.
La siguiente página recoge los últimos artículos sobre Part of Speech tagging:
3.2.7. Recursos.#
Cualquier sistema de PLN parte de un PoS tagger. Es el análisis básico. Hay muchos disponibles por la web:
SpaCy: https://spacy.io/
NLTK: http://www.nltk.org/
Standford CORE NLP: https://stanfordnlp.github.io/CoreNLP/
Google CLOUD: https://cloud.google.com/natural-language/
En CLARIN hay también varios PoS_taggers: https://www.clarin.eu/resource-families/tools-part-speech-tagging-and-lemmatisation
En OpenNLP (Java): https://opennlp.apache.org/docs/
y muchos más…
Lectura obligatoria
Para completar esta sección, lee la introducción y los apartados 8.1 y 8.2 del capítulo 8 del libro de Jurafsky y Martin (2022) Speech and Language Processing.
3.3. Análisis sintáctico.#
La sintaxis es el área de la lingüística que estudia cómo se relacionan las palabras dentro de una oración: cómo se agrupan y qué tipo de relación establecen entre ellas.
En Procesamiento del Lenguaje Natural, a la herramienta encargada de realizar el análisis sintático se le da el nombre genérico de parser y a la tarea parsing (como en los compiladores de lenguajes de programación).
En el proceso de interpretación automática de un texto, es necesario conocer las relaciones sintácticas porque de ellas dependen diversos aspectos semánticos. Si te fijas en el siguiente ejemplo, verás dos oraciones con las mismas palabras (“subir”, “tender” y “a”) y la misma categoría gramatical (verbo infinitivo, verbo infinitivo y preposición), pero con sentido totalmente diferente. Son las relaciones sintácticas las que nos indican la interpretación correcta de cada una:
No es lo mismo “subir a tender” que “tender a subir”.
En minería de textos, sin embargo, no es realmente una tarea de PLN que se utilice mucho: requiere tiempo de procesamiento (que aumenta cuanto más grande es el corpus) y no aporta la suficiente información como para que valga la pena ese gasto computacional. La sintaxis es necesaria, sobre todo, para cuando se necesita análisis de precisión.
En esta sección se exponen los fundamento del análisis sintáctico computacional, el análisis de dependencias y se muestran algunas herramientas disponibles para aplicar en minería de textos.
3.3.1. Arquitectura estándar de un parser#
La siguiente imagen muestra la arquitectura básica de un parser:
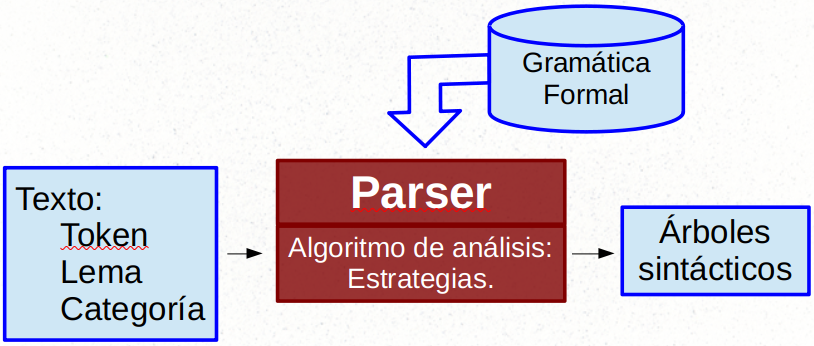
Como se puede observar, la entrada del parser es la salida del analizador categorial. De hecho el parser necesita saber (en principio) la categoría gramatical de las palabras para poder establecer las relaciones sintácticas entre ellas. La salida suele ser en forma de árbol, donde las palabras están relacionadas entre sí mediante arcos. En la siguiente sección se mostrarán los principales tipos de árboles sintácticos.
El parser necesita un recursos para realizar el análisis que se suele denominar “gramática”. Esta contiene las reglas para establecer las relaciones. En los inicios del PLN, estas gramáticas se realizaban a mano: eran gramática pequeñas con muy poca cobertura. Hoy día, al igual que en el análisis categorial, las gramáticas se realizan con modelos de aprendizaje automático, y se aplican reglas manuales solo para ganar precisión en casos concretos. Las últimas propuestas están basadas en modelos neuronales, que se ha demostrado son capaces de inferir relaciones sintácticas sin necesidad de una gramática previa.6
3.3.2. Principal problema computacional#
Asignar relaciones a palabras a partir de categorías gramaticales es una tarea hasta cierto punto viable. El gran problema que debe resolver un parser es la ambigüedad estructural: cuando es posible derivar dos o más árboles sintácticos de la misma oración. La resolución de esta ambigüedad requiere en muchas ocasiones información semántica y conocimiento del mundo (para realizar una interpretación coherente), aspectos estos que salen fuera del análisis sintáctico propiamente dicho.
A continuación se muestran dos casos de ambigüedad estructural. En este primer ejemplo (ya visto en el tema anterior), la ambigüedad viene producida por el sintagma preposicional “con los prismáticos”, que puede ser tanto complemento de “hermano” como del sujeto “yo”:
“Ayer vi a tu hermano con los prismáticos.”
En el siguiente ejemplo es la coordinación la que está generando la ambigüedad. El adjetivo “limpios” puede ser complemento solo de “cubiertos” o de la coordinación completa “los platos y los cubiertos”. En uno u otro caso, el árbol sintáctico cambia:
“Sirve los platos y los cubiertos limpios.”
El parser debe incluir, por tanto, algoritmos de desambiguación que decidan, en casos como estos, qué árbol sintáctico sería el más apropiado.
3.3.3. Modelos de representación#
En PLN hay dos modelos de representación sintáctica: los modelos basados en constituyentes y los modelos basados en dependencias. Cada uno representa algún aspectos concreto de la sintaxis y está motivado por diferentes teorías lingüísticas. Antes de utilizar un parser para hacer minería de textos, es necesario saber en qué modelo está basado para saber qué información nos va a dar.
Lo que viene a continuación igual te recuerda las clases de bachillerato.
El modelo basado en constituyentes realiza dos tareas: primero agrupa las palabras en unidades complejas llamados “sintagmas” (phrases en inglés). Un sintagma puede contener tanto palabras como otros sintagmas. Así, de abajo arriba, las palabras con relación sintáctica estrecha se agrupan en sintagmas, estos a su vez se agrupan en sintagmas complejos hasta llegar a la agrupación final que es toda la oración. Cada una de estas agrupaciones recibe el nombre de constituyente oracional.
La segunda tarea es determinar el tipo de sintagma: nominal, verbal, preposicional, adjetivo, etc. El tipo de sintagma depende siempre de la palabra que actúa como núcleo sintagmático (un nombre, una preposición, un adjetivo…). El sintagma que los agrupa a todos es la oración y su núcleo, normalmente, un verbo.
La siguiente imagen es un ejemplo de árbol de análisis basado en constituyentes:
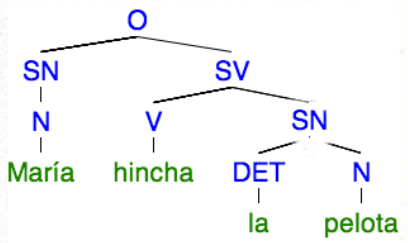
En este caso tenemos dos sintagmas nominales (SN), un sintagma verbal (SV) y la oración. En la herramientas de PLN lo normal es que te encuentres esos sintagmas con las siglas en inglés: “NP” para nominal phrase, “PP” para prepositional phrase, “VP” para verbal phrase, etc.
El modelo basado en dependencias es diferente. No le interesa tanto mostrar cómo se agrupan las palabras según su relación sintáctica, como mostrar qué relación o dependencia tienen unas palabras con otras. La dependencia se produce siempre entre dos palabras: una actúa de núcleo (head) y otro que actúa de “dependiente” (dependent) o complemento. El análisis de dependencias también supone dos tareas: primer detectar de quién depende cada palabra de la oración, y segundo determinar el tipo de dependencia: sujeto, objeto, complemento, especificador… Los árboles de dependencias suelen tener forma de grafo con nodos/hojas (las palabras) y arcos dirigidos (el tipo de dependencia entre dos nodos), como muestra la siguiente imagen:
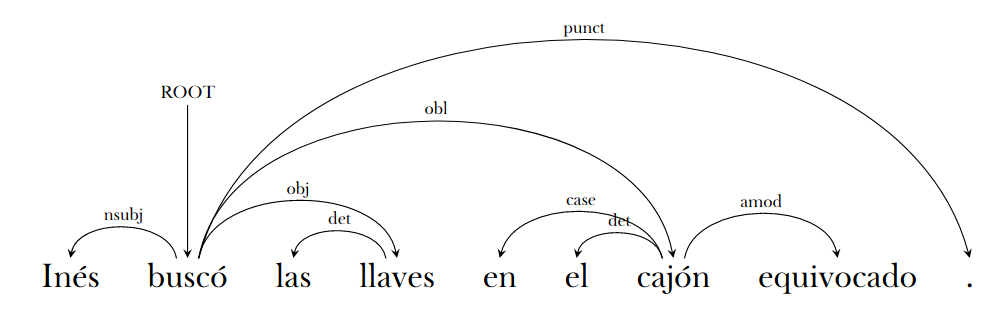
En este ejemplo podemos ver que el núcleo oracional (root) es el verbo “buscó”. De este dependen tres palabras: “Inés” con una dependencia de nsubj (sujeto nominal), “llaves” con una dependencia de obj (lo que en la gramática escolar se denomina “complemento directo” u “objeto directo”) y “cajón” con una dependencia de obl (de oblique o adjunct, que vendría a ser un complemento circunstancial). A su vez, “llaves” y “cajón” son núcleo de otras palabras, etc.
Hoy día el modelo más común es el de dependencias, sobre todo porque hace una representación de la relación sintáctica más explícita. Pero antes de profundizar en él, y para entender bien cómo funciona un parser, vamos a ver los modelos de constituyentes.
3.3.4. Gramáticas formales#
La parte principal del un parser es la gramática: el conjunto de reglas que, dado una secuencia de tokens (y en su caso también categorías gramaticales) derivan un árbol sintáctico. Estas deben ser reglas formales que la máquina puede entender y procesar.
3.3.4.1. Context free grammars#
Las gramáticas independientes del contexto (CFG: Context free grammars) es el formalismo base de toda una familia de gramáticas formales que se desarrollaron después. La definición formal es la siguiente:
G = (NT, T, S, P)
NT: {no terminales},
T: {terminales},
S: Símbolo inicial
P: Reglas de producción A -> w:
A NT
W (NT U T)*
Una CFG es una tupla de cuatro elementos: un conjunto de símbolos no terminales, un conjunto de símbolos terminales, un símbolo inicial, y una serie de reglas de producción con la forma \(A \to w\), en la que los símbolos de la izquierda (\(A\)) tienen que ser siempre no terminales, y los de la derecha \(w\) pueden ser tanto terminales como no terminales.
Ejemplo:
NT={S,NP,VP,nprop,n,v,det},
T={Pepe,manzana, come,una},
S=S,
P:
S -> NP VP
NP -> nprop
NP -> det n
VP -> v
VP -> v NP
En este caso los símbolos no terminales son las etiquetas sintácticas y categoriales (S, NP, VP, nprop, n, v, det), los símbolos terminales son los tokens (“Pepe,manzana, come,una”), el símbolo inicial es \(S\) y las reglas de producción indica cómo cada símbolo no terminal se puede transformar en otros símbolos. De esta gramática se podría derivar el siguiente árbol:
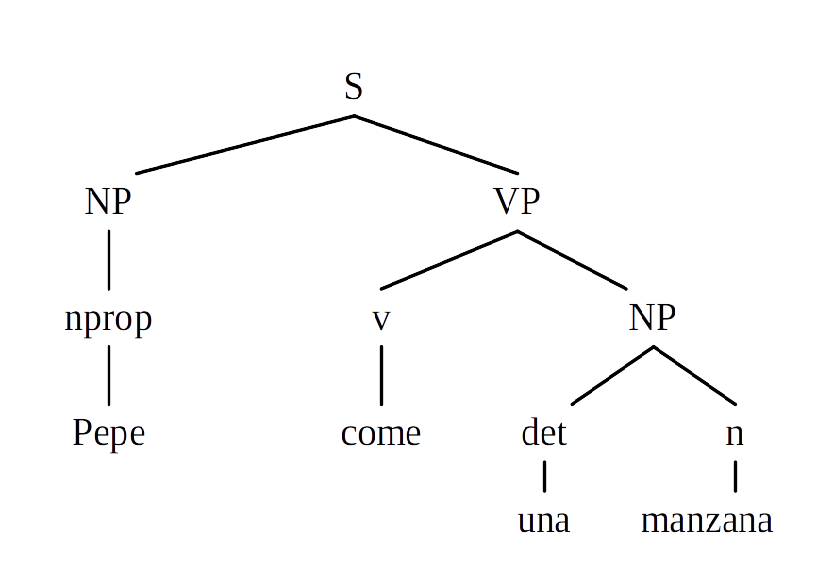
Estas gramáticas son, por supuesto, muy limitadas. Sólo sirven para conjuntos predefinidos de oraciones. En los años 80 fueron ampliadas con estructuras de rasgos y técnicas de unificación. Las estructuras de rasgos son estructuras asociadas a cada símbolo (tanto terminal como no terminal) que permiten enriquecerlo con datos (pares atributo-valor). En el ejemplo siguiente se puede ver una estructura de rasgos con información morfológica. La unificación es una operación que permite comparar y, si son compatibles, unir dos estructuras de rasgos. La siguiente imagen muestra un caso de unificación porque las dos estructuras de rasgos son compatibles:
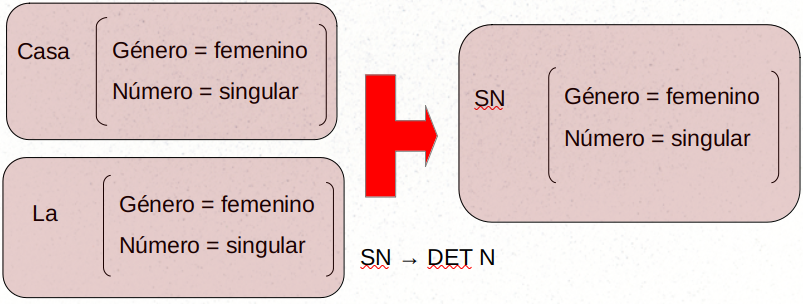
Si en vez de “La casa”, la oración de entrada fuera “El casa”, la regla \(SN \to DET N\) no se aplicaría porque la estructura de rasgos sería incompatible. El género de “el” sería masculino y el de “casa” femenino. Este simple caso de concordancia se puede modelar bien con estructuras de rasgos.
A partir de estos formalismos, en lingüística se han desarrollado diferentes modelos completos com las Head-driven phrase structure grammar o las Lexical-Functional Grammar (que sigue siendo un modelo válido y objeto de investigación lingüística: https://ling.sprachwiss.uni-konstanz.de/pages/home/lfg/).
3.3.4.2. Modelos probabilísticos#
Si bien estos formalismo son hoy válidos para el estudio lingüístico por permitir una forma elegante de tratar los rasgos, no son útiles para Procesamiento del Lenguaje Natural. Entre otras cosas, no son capaces de dar solución a la ambigüedad estructural que se comentó antes.
Una solución a este problema fueron las gramáticas probabilísticas, como la Probabilistic Context Free Grammar. Este modelo simplemente incluye un valor probabilístico de aplicación de la regla (que ha aprendido a partir de corpus anotados mediante aprendizaje supervisado). Este peso estadístico permite decidir qué regla aplicar en según qué casos:
SV → V SP SP (0.5)
SV → V SP (0.3)
SV → V (0.2)
Con la aplicación del aprendizaje supervisado al análisis sintáctico se desarrollaron los treebanks: corpus de texto anotados a mano con árboles sintácticos. Estos se utilizan tanto como corpus de aprendizaje como corpus de evaluación para todo tipo de sistemas. Dos de los treebanks más conocidos, uno para para inglés y otro para español, son:
Penn Treebank:
Ancora (español, catalán):
Hay muchos más para diferentes idiomas.
3.3.5. Chunkers#
Hasta ahora el análisis sintáctico se ha planteado como un análisis completo (full parsing): derivar el árbol entero en toda su profundidad. Dada la complejidad que una oración real puede tener, este tipo de análisis resulta en muchas ocasiones muy complejo o incluso imposible, además de consumir mucho tiempo y recursos para obtener resultados no del todo buenos.
En los años 90 se propuso una solución a este problema: el chunkers o análisis sintáctico parcial (Abney 1991). Un análisis sintáctico parcial no deriva el árbol sintáctico completo de una oración, sino solo deriva el árbol de algunos sub-árboles. De un oración se pueden derivar, por ejemplo, solo los sintagmas nominales y verbales, sin llegar a construir un único árbol completo. Cada uno de estos sub-árboles es un chunk.
En análisis de constituyentes lo normal es realizar análisis parcial. Con ello se gana en velocidad y recursos.
3.3.6. Estrategias#
Hay dos tipos de estrategias de análisis: la descendente y la ascendente.
La descendente comienza el análisis con el símbolo inicial \(S\) y va derivando el árbol mediante la aplicación de las reglas en orden hasta llegar a analizar todos los símbolos terminales.
Con la herramienta NLTK instalada, puedes ver de manera gráfica cómo funciona un analizador descendente recursivo con el siguiente código:
import nltk
nltk.app.rdparser()
El ascendente parte de los símbolos terminales y, mediante las reglas, trata de llegar hasta el símbolo inicial. El modelo shift-reduce, por ejemplo, va seleccionando token a token (shift) y, cuando estos responden a un símbolo no terminal, los agrupa (reduce). Luego repite ambos procesos con los símbolos no terminales hasta alcanzar el símbolo inicial. Por ejemplo, la regla \(SN \to DET N\) agruparía un determinante con un nombre. Puedes ver una muestra grafica de este algoritmo con el siguiente código de NLTK:
import nltk
nltk.app.srparser()
3.3.7. Análisis de dependencias#
3.3.7.1. Formato de representación: CONLL#
Si bien hay diferentes formatos para representar el análisis de dependencias, el más común hoy día es el formato CONLL. Aquí puede ver un ejemplo:
Salida CoNLL-U
# sent_id = 1
# text = Los hombres que fuman puro tienen cara de canguro .
1 Los el DET DET Definite=Def|Gender=Masc|Number=Plur|PronType=Art 2 det _ _
2 hombres hombre NOUN NOUN Gender=Masc|Number=Plur 6 nsubj _ _
3 que que PRON PRON PronType=Int,Rel 4 nsubj _ _
4 fuman fumar VERB VERB Mood=Ind|Number=Plur|Person=3|Tense=Pres|VerbForm=Fin 2 acl _ _
5 puro puro ADJ ADJ Gender=Masc|Number=Sing 4 obj _ _
6 tienen tener VERB VERB Mood=Ind|Number=Plur|Person=3|Tense=Pres|VerbForm=Fin 0 root _ _
7 cara cara NOUN NOUN Gender=Fem|Number=Sing 6 obj _ _
8 de de ADP ADP _ 9 case _ _
9 canguro canguro NOUN NOUN Gender=Masc|Number=Sing 7 nmod _ _
10 . . PUNCT PUNCT PunctType=Peri 6 punct _ _
Cada línes es un token. La primera columna es un índice, y las siguientes corresponden a: token, lema, categoría gramatical, información morfológica (opcional). Las dos última columnas indican el número de identificación de la palabra de quien es núcleo y la relación de dependencia con éste. Así se determina la dependencia y con ello el árbol. El inicio del árbol lo marca siempre la etiqueta root (en la palabra 6 en este caso).
3.3.7.2. Dependencias universales#
Esas etiquetas sintácticas responden al tag set de las dependencias universales o Universal Dependencies (Nivre et al., 2016). Este modelo es hoy el más utilizado por diversas razones. Entre otras cosas, está bien motivado desde un punto de vista lingüístico, pero al mismo tiempo es útil desde el punto de vista computacional y es “multilingüe, lo que permite tratar corpus con textos en diferentes idiomas con una representación sintáctica común.
Sin entrar en detalles, las principales etiquetas sintácticas que pueden a aparecer en un análisis de dependencias con las dependencias universales son:
nsubj (sujeto nominal): https://universaldependencies.org/u/dep/nsubj.html
obj (objecto directo): https://universaldependencies.org/u/dep/obj.html
iobj (objeto indirecto): https://universaldependencies.org/u/dep/iobj.html
obl (oblique nominal), otros complementos del verbo: https://universaldependencies.org/u/dep/obl.html
nmod (nominal modifier o complemento del nombre): https://universaldependencies.org/u/dep/nmod.html
etc.
Puedes consultar todas las relaciones aquí: https://universaldependencies.org/u/dep/index.html
3.3.7.3. Análisis#
El análisis de dependencias estándar es el análisis basado en transiciones: transition-based dependency parsing (Nivre 2014), que es un tipo de análisis shift-reduce.
Lectura obligatoria
Para completar este tema, lee con atención la introducción y el apartado 18.1 del capítulo “18 Dependency Parsing” del libro de Jurafsky y Martin (2022) Speech and Language Processing. Lee también el partado 18.2 “Transition-Based Dependency Parsing”, pero sin entrar en detalles. El objetivo es que tengas una idea general de este algoritmo. El resto del capítulo es lectura opcional.
3.3.8. Situación actual#
La situación actual del análisis sintáctico se caracteriza por:
la aplicación de modelos neuronales como el Neural Network Dependency Parser (https://nlp.stanford.edu/software/nndep.shtml),
con ello, la representación de información sintáctica en embeddings como vectores (de lo que se hablará en los siguientes temas), y
las dependencias universales.
Ver:
3.3.9. Herramientas#
Hay multitud de herramientas para realizar análisis sintáctico. Aquí cuatro de las más conocidas:
SpaCy: https://spacy.io/
Freeling: https://nlp.lsi.upc.edu/freeling/node/1
UD-Pipe: https://ufal.mff.cuni.cz/udpipe
En la práctica se utilizará SpaCy.
3.4. Bibliografía#
Abney S.P. (1991) “Parsing By Chunks”. In: Berwick R.C., Abney S.P., Tenny C. (eds) Principle-Based Parsing. Studies in Linguistics and Philosophy, vol 44. Springer, Dordrecht. https://doi.org/10.1007/978-94-011-3474-3_10
Emily M. Bender (2013) Linguistic Fundamentals for Natural Language Processing. 100 Essentials from Morphology and Syntax, Synthesis Lectures on Human Language Technologies DOI: https://doi.org/10.1007/978-3-031-02150-3
Steven Bird, Ewan Klein, and Edward Loper (2009) Natural Language Processing with Python https://www.nltk.org/book/
Jurafsky y Martin (2020) Speech and Language Processing. https://web.stanford.edu/~jurafsky/slp3/
Karlsson, F., A. Voutilainen, J. Heikkilä, and A. Anttila (eds.). 1995. Constraint Grammar. A language-independent system for parsing unrestricted text. Berlin and New-York: Mouton de Gruyter
3.5. Cuestionario de aprendizaje#
Una vez realizadas las lecturas, contesta el siguiente cuestionario:
https://forms.gle/ncbWkFGCjSqXSTiX9
- 1
“Token” se asimila en este caso a “occurrence”. Cfr. https://plato.stanford.edu/entries/types-tokens/#Occ
- 2
Ver capítulo 3 del libro Natural Language Processing with Python para una explicación sencilla.
- 3
Bender (2013) presenta una buena introducción a conceptos lingüísticos de uso común en Procesamiento del Lenguaje Natural.
- 4
Greene, B. B. and G. M. R.ubin (1971). “Automatic grammatical tagging of English. Technical report”, Department of Linguistics, Brown University, Providence, Rhode Island.
- 5
Karlsson, Voutilainen, Heikkilä and Antilla (eds) 1995. Constraint Grammar: A Language-Independent System for Parsing Unrestricted Text. Mouton de Gruyter, Berlin and New York.
- 6
Ver, entre otros, Ethan A. Chi, John Hewitt, and Christopher D. Manning (2020) “Finding Universal Grammatical Relations in Multilingual BERT” In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 5564–5577. Association for Computational Linguistics. https://aclanthology.org/2020.acl-main.493/